

This article highlights some interesting work from Gravic Labs, Gravic’s Research and Development group, in the area of increasing the data integrity of mission critical systems. The article expands on our talk at The Connect NonStop TBC meeting in October 2021, and is a continuation of the topic that we presented in the July/August 2017 issue of The Connection[1].
Note that we present some of Gravic’s technology that is not yet designated for a specific product release. After reading this article, please contact us if you would like to discuss your needs and our product plans for this interesting technology.
RAS: Three Pillars of Mission Critical Computing
The three pillars of mission-critical computing are Reliability, Availability, and Scalability[2]. Their relationship is often depicted on the vertices of an equilateral triangle since they have equal, critical importance.
To define the three pillars of RAS more thoroughly:
 Reliability is a measure of how well a system returns the same correct, consistent, and uncorrupted results each time, and relies on the underlying integrity of the database, application, and system components;
Reliability is a measure of how well a system returns the same correct, consistent, and uncorrupted results each time, and relies on the underlying integrity of the database, application, and system components;- Availability is the percent of uptime achieved by the application in servicing users; and
- Scalability is the capability to add resources when needed to handle the application load, and to return those resources when no longer needed.
Our other papers and books mentioned in the Gravic Shadowbase talks at the recent Connect NonStop Technical Boot Camp (TBC) cover the architectures used for maximizing availability and scalability[3].
In this article, we are going to focus in-depth on some new concepts we have named Validation Architectures for maximizing reliability and its associated data integrity requirement and we will present a proof of concept (POC) use case.
High availability and scalability get the vast majority of attention in talks about mission-critical systems. In fact, our Shadowbase business continuity suite, globally marketed by HPE as HPE Shadowbase, is promoted for its continuous availability and scalability capabilities via our active/active technology.
 Reliability: The Elephant in the Room
Reliability: The Elephant in the Room
Reliability, however, is the elephant in the room as many computer companies no longer focus on it and even omit it from their literature and talks. Yet, problems with data integrity are prevalent and can arise from software bugs, hardware errors, malware, and many other problems. For example, problems with Intel CPUs have been in the news a lot recently – Meltdown, Spectre, Rowhammer, and many other variant problems affect hardware. Software is in the same situation with almost daily announcements of major data breaches and hack.



Many articles and talks discuss the terms Recovery Point Objective (RPO) and Recovery Time Objective (RTO) for the concept of availability as depicted in Figure 1. See the reference section at the end of the article for useful links on RPO and RTO.
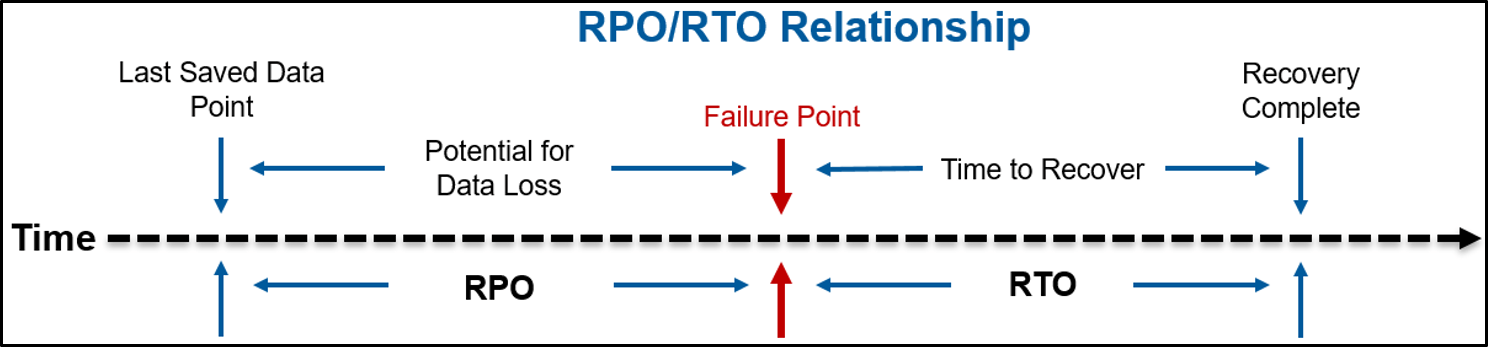
Figure 1 – Availability Metrics: Recovery Point Objective (RPO) and Recovery Time Objective (RTO)
Here, we extend the concepts of RPO/RTO to data integrity via the Integrity Point Objective (IPO) and Integrity Time Objective (ITO) terms as shown in Figure 2.
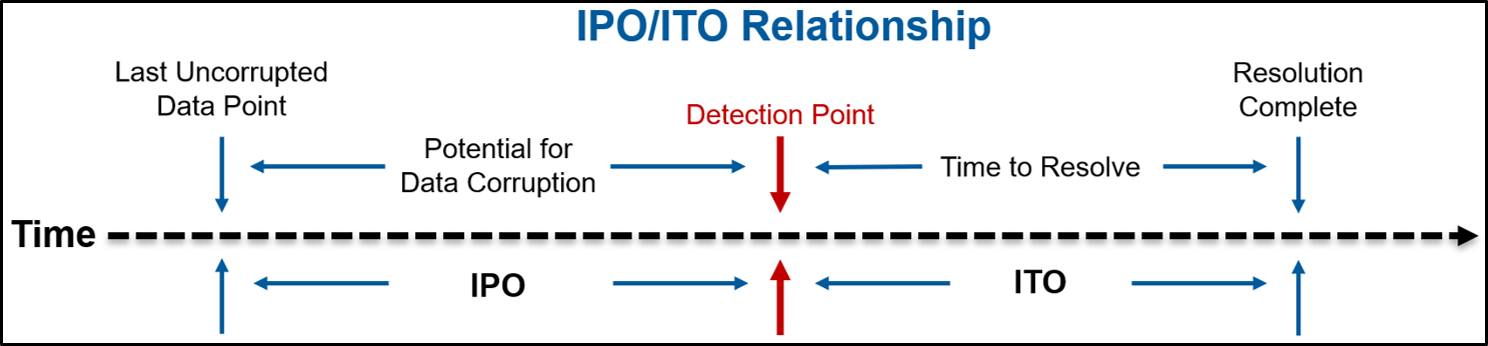
Figure 2 – Reliability Metrics: Integrity Point Objective (IPO) and Integrity Time Objective (ITO)
How much data corruption can be tolerated and how long can be taken to resolve those data integrity problems? Businesses with mission-critical applications must seek to drive RPO, RTO, and IPO, ITO all to zero.
Validation Architectures for Data Integrity
We introduce Validation Architectures to illustrate how to maximize data integrity and reliability. For those familiar with early generation HPE NonStop systems, they echo the concepts of lock-step CPUs and the Logical Synchronization Unit, except solving the problem for modern transaction processing systems using hyper-threaded, non-deterministic CPUs.
We have defined three levels of Validation Architecture for transaction validation. Level 0 is the most basic, and Level 2 is the most advanced. All three levels make use of a Transaction Duplicator that routes the request (User Transaction) to independent processing nodes as shown in Figure 3.
![]()
Figure 3 – Transaction Duplicator
The transaction duplicator can be custom implemented or use a tool such as NGINX or Apache Camel. On HPE NonStop, Apache Camel is called NSMQ.
Offline Transaction Validation: Level 0 Architecture
Offline Transaction Validation as shown in Figure 4 uses the transaction duplicator to route the identical copies of a request to two independent nodes running the same application. Periodic (e.g., hourly or daily), database compares are run using a tool like Shadowbase Compare to ensure data integrity in the databases.
![]()
Figure 4 – Level 0 Offline Transaction Validation
Asynchronous Transaction Validation: Level 1 Architecture
Asynchronous Transaction Validation as shown in Figure 5 operates like Level 0, but for each transaction that is fully processed and committed on the nodes, indicia of the transaction outcome is calculated and exchanged between the processing nodes. If a mismatch happens, immediate action can be taken like logging the problem, sending out alerts, and even undoing or reversing the damage caused by the transaction with a tool like Shadowbase UNDO.
![]()
Figure 5 – Level 1 Asynchronous Transaction Validation
Synchronous Transaction Validation: Level 2 Architecture
Synchronous Transaction Validation as shown in Figure 6 is a major step beyond Level 1 as the validation processes actually join the applications’ TMF transactions as voting members. Similar to Level 1, indicia are computed and exchanged, and the underlying transactions are either committed or aborted, thereby preventing any form of data integrity problems from proceeding and propagating throughout the system.
![]()
Figure 6 – Level 2 Synchronous Transaction Validation
These three types of Validation Architectures implement Dual Server Reliability (DSR). In some mission-critical and life preserving applications, the capability to eject a compromised node and continue processing may be necessary if a problem is detected.
Triple Server Reliability
Triple Server Reliability (TSR) may be utilized where the majority rules. It would be nearly impossible for a hacker to simultaneously corrupt two or three different systems, especially if the nodes are hosted in different datacenters using different operating systems and application environments. The difference is depicted in Figure 7.
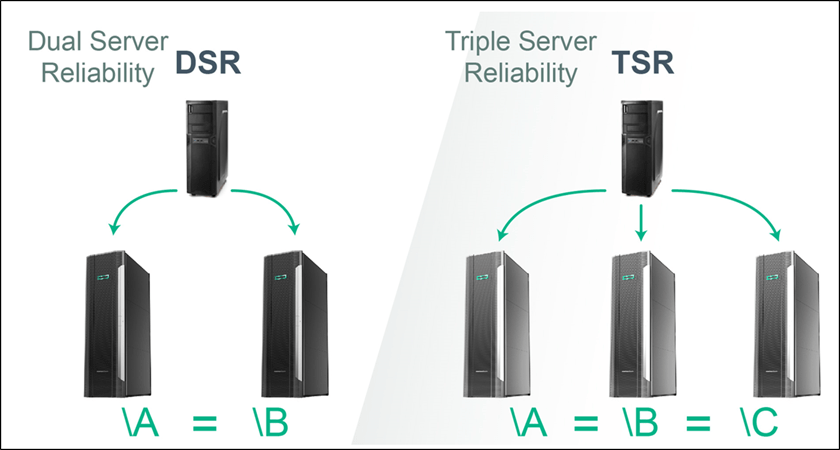
Figure 7 – Dual and Triple Server Reliability
Best of Both Worlds Implementation
Note that active/active data replication is ideal for applications needing high availability and scalability since it provides the best RTO and RPO rates in the industry. Combined with a Validation Architecture, we can add high data integrity in order to achieve the best ITO and IPO rates, what we call a best of both worlds implementation.
As an example, the left three systems shown in Figure 8 are working together as a Validation Architecture system, and so are the right three systems.
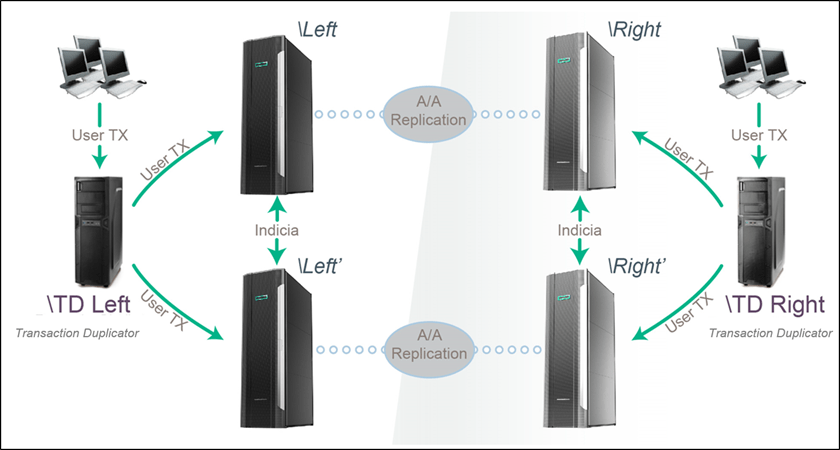
Figure 8 – Best of Both Worlds: Active/Active Architecture for Availability/Scalability
and Validation Architecture for Data Integrity
Active/active replication works together with the Validation Architecture to allow transactions to be sent either to the left or right transaction distributors. The result is maximizing all three: Reliability, Availability, and Scalability.
Balloting Use Case Proof of Concept (POC) for Election Fraud Prevention
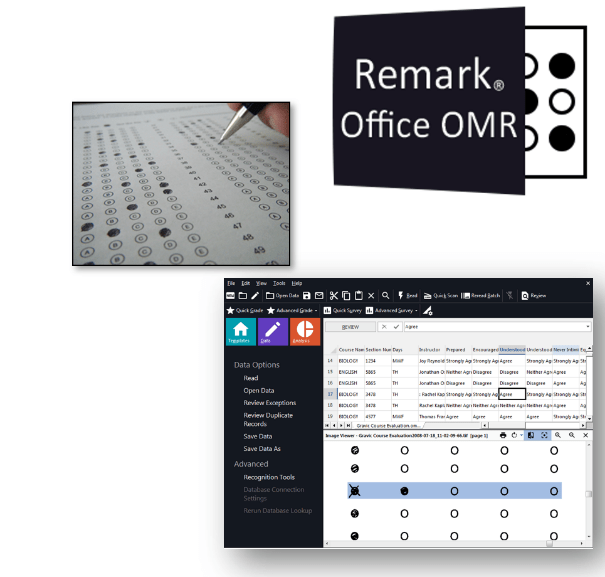
Gravic’s Remark Products Group manufactures optical mark recognition software for image scanners for:
-
- Over 100,000 customers
- in 130+ countries
- processing millions to billions of forms each year
- in primary and higher education, government, corporate, healthcare, and non-profit fields.
Remark OMR software is used worldwide for balloting and elections.
Unfortunately, a large percentage of people no longer fully trust the election process. The POC is trying to solve this significant societal problem. This distrust can be attributed to the perceived or actual lack of integrity and validation of election results. In the U.S. 2020 election season, several companies lost billions of dollars in market value since their integrity was questioned.
Thus, a method is needed to hold and process elections with unchallengeable and verifiable data integrity. When we say elections, we mean all elections. Government elections can include federal, state, and local ones, such as school board elections. Corporate elections include shareholder and proxy ballots, and union elections include letter carriers, teachers, construction, and manufacturing sectors. Of course, non-profits also hold many types of elections.
The POC solution chosen for this growing problem combines the patented Remark Cloud and Shadowbase replication technologies in a Validation Architecture and provides high levels of reliability, availability, and scalability. The solution also leverages ubiquitous and cost-effective vendors and cloud providers.
As shown in the POC architecture in Figure 9, many form scanners on the left side of the figure are geographically distributed as needed and are used to handle the ballot volume. The processing steps will now be described.
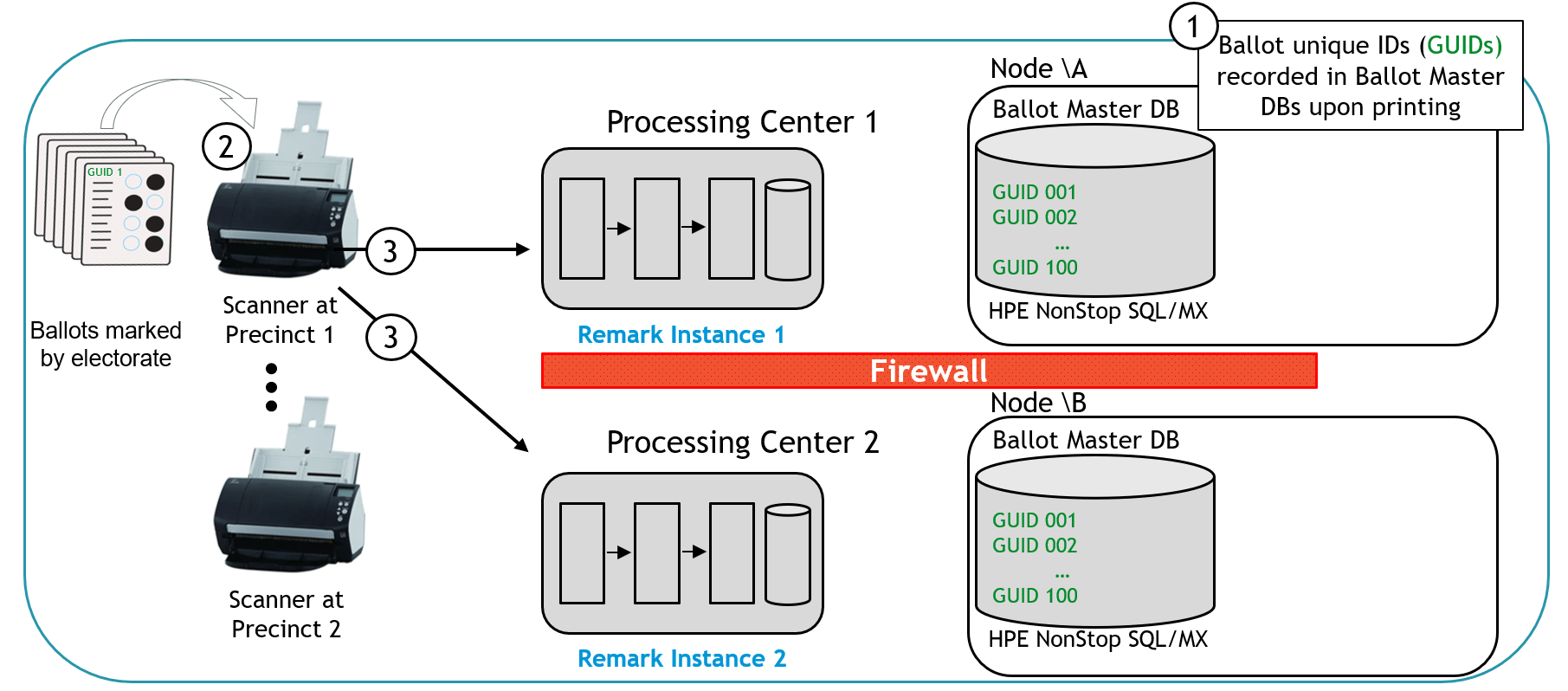
Figure 9 – Level One Validation Architecture: Steps 1-3
-
-
- Batches of physical, paper ballots are printed with unique IDs (GUIDs), which are recorded in both copies of the Ballot Master Database.
- Ballots are marked by the electorate at a precinct and are submitted for scanning at the precinct’s workstation.
- The workstation duplicates and sends a request containing the images for each batch of ballots to two separate Remark Cloud instances, Remark Instance 1 and 2. Notice that the Remark instances are running on two separate Cloud providers, with an isolating firewall in between and no method of communication between them.
- As shown in Figure 10, each Remark Cloud instance processes the ballot images, operating independently on separate networks.
-
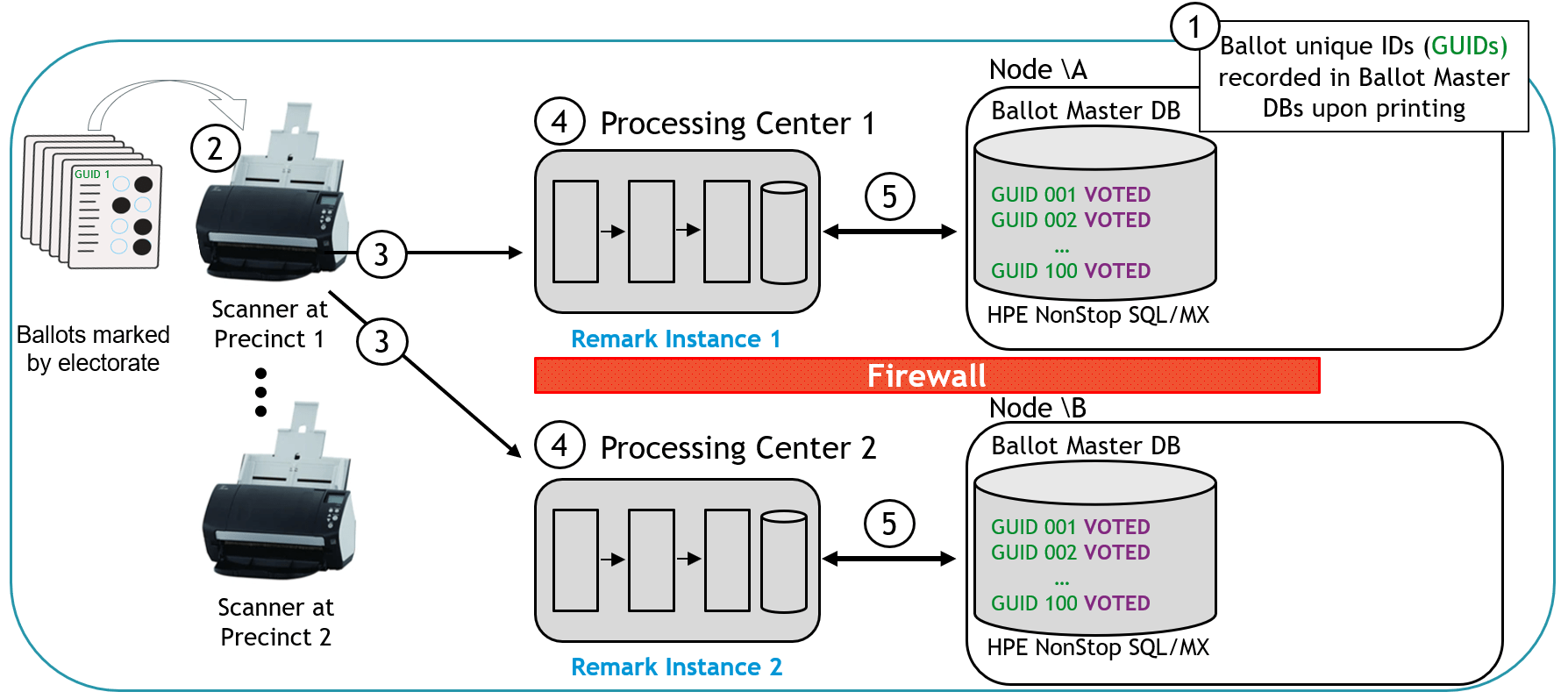
Figure 10 – Level One Validation Architecture: Steps 4-5
-
-
- The Remark Cloud instances update their respective HPE NonStop Ballot Master Database with the ongoing ballot recognition results.
- As shown in Figure 11, Shadowbase VA components on each NonStop node generate a hash for each transaction batch of ballots and then exchange the values with each other.
- If the results match after the comparison, then the results are considered validated in the Ballot Master Database.
-
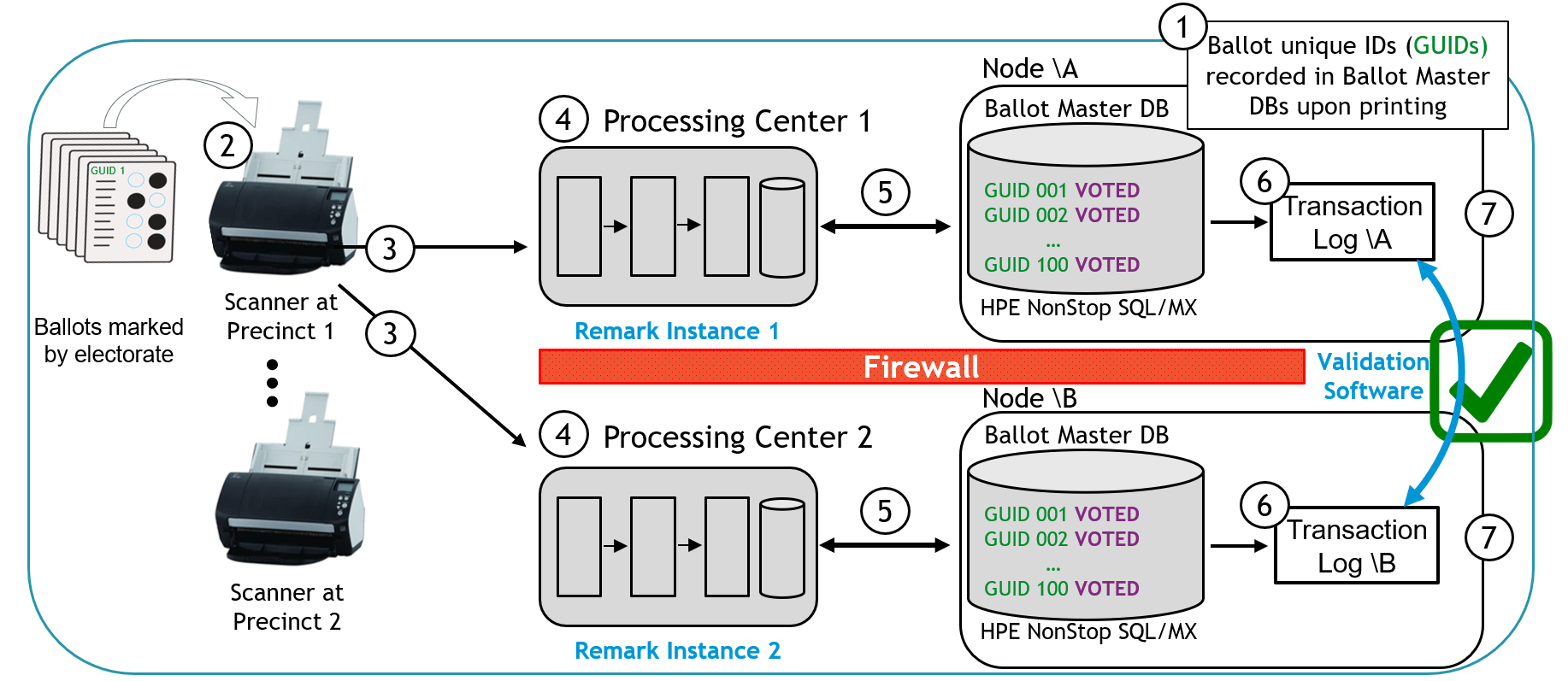
Figure 11 – Level One Validation Architecture: Steps 6-7
However, if the results do not match, then the mismatch is reported and the ballot batch is marked for further review as shown in Figure 12.
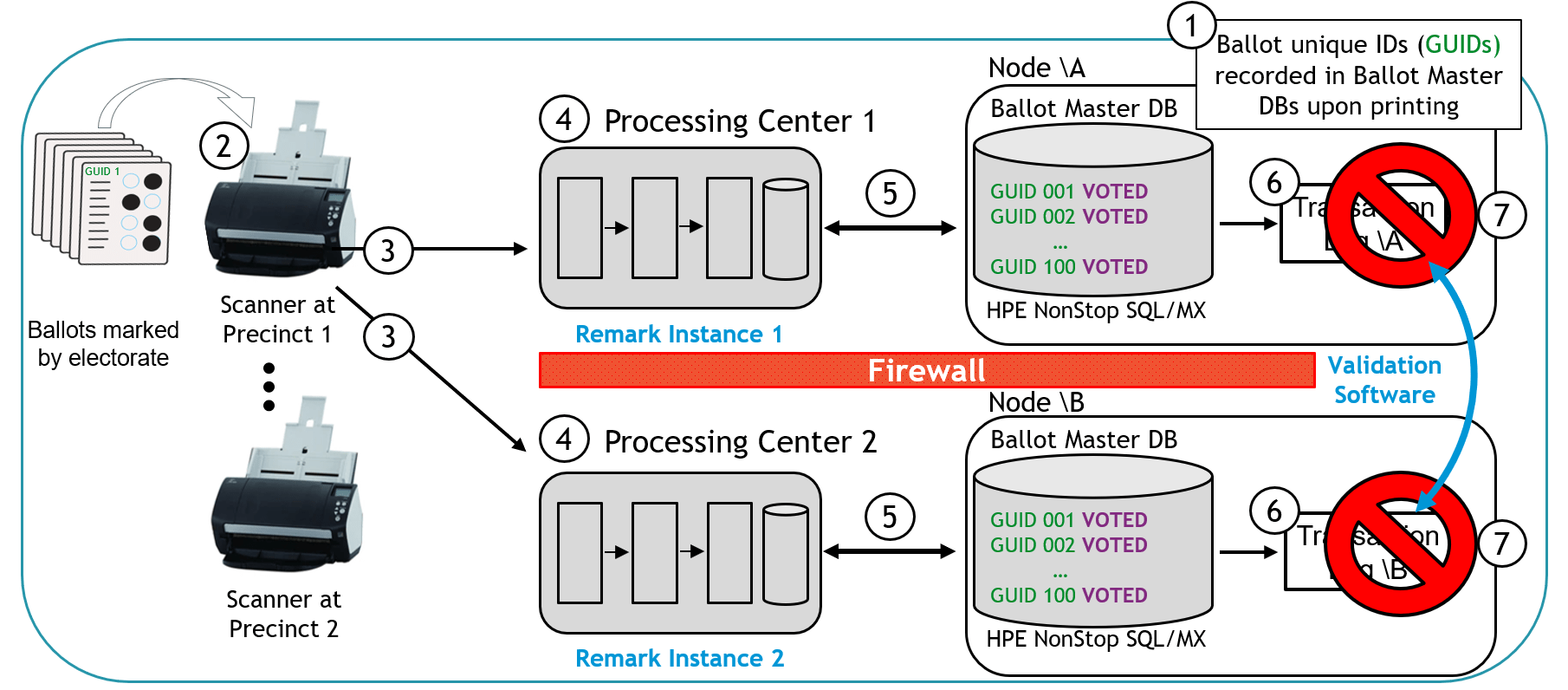
Figure 12 – Level One Validation Architecture: Detecting Ballot Mismatches
POC Benefits
This solution solves the following issues:
-
-
- Catches unauthorized ballot copying as the GUIDs are unique,
- Allows for rescanning of ballots with no risk of duplicative counting,
- Prevents hackers from invading a processing stream undetected and changing results,
- Prevents insider attacks if the processing centers are managed by different staff,
- Eliminates the need for transporting the marked ballots between precincts, and
- Hackers seeking to change election results are immediately caught before they cause significant damage.
-
Overall security can benefit from deployment in private datacenters and clouds. The potential go-to-market solution from the POC is expected to be high-profile and significantly contribute to the democratic voting process. The authors view the POC as an example of Gravic’s Core Purpose of Improving Society Through Innovation. We are open and very interested in talking with other HPE partners interested in working with us on this endeavor. Please Contact Us.
References and Links
1. Technical Boot Camp Talk
2. General Information on the RAS Topic
3. Breaking the Availability Barrier — Active/Active Systems
-
-
- Books — Breaking the Availability Barrier by Dr. Bill Highleyman, Paul J. Holenstein, and Dr. Bruce Holenstein
-
4. Patent Family References for Validation Architecture Systems
-
-
- US 10,152,506 — Method of ensuring real-time transaction integrity
- US 10,467,223 — Mixed-mode method for combining active/active and validation architectures
-
5. Short Video Cartoon on a Financial Industry Application of a Validation Architecture
6. Remark and Shadowbase Software
-
-
- Remark Products Group RemarkSoftware.com
- Shadowbase Products Group ShadowbaseSoftware.com
-
7. Hardware and Software Integrity Issues in Current News
Specifications subject to change without notice. Trademarks mentioned are the property of their respective owners. Copyright 2021.
About the Authors
 Dr. Bruce Holenstein, President and CEO, Gravic. Inc.
Dr. Bruce Holenstein, President and CEO, Gravic. Inc.
Dr. Holenstein leads all aspects Gravic, Inc. as its President and CEO. He started company operations with his brother, Paul, in 1980, and is presently leading the company through the changes needed to accommodate significant future growth. His technical fields of expertise include algorithms, mathematical modeling, availability architectures, data replication, pattern recognition systems, process control, and turnkey software development. Dr. Holenstein is a well-known author of articles and books on high availability systems. He received his BSEE from Bucknell University and his Ph.D. in Astronomy and Astrophysics from the University of Pennsylvania.
 Mr. Paul J. Holenstein, Executive Vice President, Gravic, Inc.
Mr. Paul J. Holenstein, Executive Vice President, Gravic, Inc.
Mr. Holenstein has direct responsibility for the Gravic, Inc. Shadowbase Products Group and is a Senior Fellow at Gravic Labs, the company’s intellectual property group. He has previously held various positions in technology consulting companies, from software engineer through technical management to business development, beginning his career as a Tandem (HPE NonStop) developer in 1980. His technical areas of expertise include high availability designs and business continuity architectures, data replication technologies, heterogeneous application and data integration, and communications and performance analysis. Mr. Holenstein holds many patents in the field of data replication and synchronization, writes extensively on high and continuous availability topics, and co-authored Breaking the Availability Barrier, a three-volume book series. He received a Bachelor of Science degree in computer engineering (BSCE) from Bucknell University, a Masters in Computer Science (MSCS) from Villanova University, and is an HPE Master Accredited Systems Engineer (MASE).
 Mr. Victor Berutti, Senior Vice President, Gravic, Inc.
Mr. Victor Berutti, Senior Vice President, Gravic, Inc.
Mr. Berutti has responsibility for the Remark Products Group at Gravic, Inc. He joined the company after working in industry as a computer software contractor. His technical areas of expertise include image scanning, pattern recognition, user interfaces, optical character and mark reading, and user requirements analysis, which are the foundations of Remark products. In addition to managing the Remark Products Group, Mr. Berutti is responsible for building and developing the international reseller channel and managing the relationships with many industry-leading companies who utilize the Remark products as part of their solutions. Mr. Berutti received his BSCS from Bucknell University and his MSCS from Villanova University.
-
-
- Please see A Modern Look at Reliability, Availability, and Scalability as seen in The Connection, by Dr. Bruce Holenstein, Paul J. Holenstein, and Dr. Bill Highleyman ↑
- Historical note for the “S” in RAS: IBM originally coined the term Serviceability for their mainframe systems, but Tandem and Compaq used the term Scalability. We continue with the latter use. ↑
- Please see the 2021 Connect TBC talk: NonStop Business Continuity Product Suite Update. ↑
-

{kind=link}
Be the first to comment