

In Japan, a lot of companies are working from home since the end of March when COVID-19 became more serious, and sales activities have been restricted. Under such circumstances, we held a Webinar on April 22nd promoting the NonStop database “SQL/ MX” so customers could participate from home. The Seminar title is “A recipe of system construction that never stops business”, and introduced how to build a system that cannot be stopped by using the NonStop Database.
As a result, 127 people registered, and 92 people participated on the day. The yield was 72%, which was higher than that of a regular face-to-face seminar. Afterward, the results of a questionaire showed that 80% of the customers indicated that they found the event to be very good or good, and the customer satisfaction was high. Here are what some Customers said:
- Under the circumstances, the Webinar seminar was appreciated.
- A case study of migration from Oracle to NonStop Database was helpful.
- It was surprising that there was a return trend from public cloud to on-premises for mission-critical system.
Many people thought it was surprising to hold a mission-critical seminar as a Webinar, but it is an effective method in this kind of situation. We predict that a paradigm shift will occur, such as seminars being offered as Webinars becoming major trend.
The number of customers who are shifting their mission-critical system from Oracle to NonStop SQL is increasing in Japan.
We have been promoting NonStop Database to customers using Oracle Database in Japan. Oracle customers have various issues such as availability / reliability, scalability, and license price increase. However, especially in mission-critical business, there weren’t many options other than Oracle Database. NonStop SQL is a product that can solve such Oracle problems as:
- Availability that continues the business in a few seconds even if a failure occurs.
- Reliability that does not cause data inconsistency or data loss even when a system outage occurs.
- Scalability that linearly improves performance by adding servers and core upgrades even when transactions increase.
Various customers such as a telecommunications carrier, a major retail distributor, and an airport management company, service provider have migrated from Oracle to NonStop. The trust network is one of them.
Here is the case study: Trust Networks, Japan Trust Networks, Japan
“The integration of the transaction management system proved effective in terms of reducing Oracle Database license costs. The annual maintenance costs of the system as a whole have been reduced by approximately 50%. It is expected that investments in the system will be recouped within five years.”
— Takuma Suzuki, Director, Trust Networks Inc.
Now I would like to briefly introduce the contents of our Webinar.
In the first half, we studied the problems that modern mission-critical systems have and clarified what the user requirements are in this cloud trend. In the second half, we introduce the characteristics of the HPE NonStop Server, which is the best platform to meets those requirements, and also introduce some case study of migration from Oracle to NonStop SQL, then concluding what is the best way to implement an optimal mission-critical system.

At the beginning, by introducing actual news articles in Japan, we showed the frequent occurrence of system outages that resulted in long business interruptions. In particular, there are more and more cases where a database server fails and causes a service outage for several days to manually recover the damaged data. In addition, it has been reported that multiple companies simultaneously experienced an operation stop for a long time due to the failure of a large managed cloud provider. We assume the problem is that availability and reliability technologies have changed little from past levels, while utilization and development technologies have made remarkable progress.
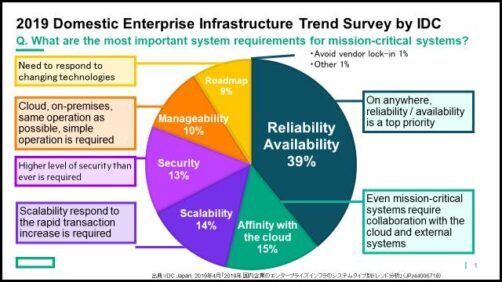
Next, we examined the results of a survey conducted by IDC on user companies. One research showed interesting results that 80% of users currently using public cloud services are now planning to bring some or all of their systems back to their on-premises. In addition, this material shows the result of a survey on the requirements for mission-critical systems. It can be easily predicted that reliability and availability will come first, but you can see the compatibility with the cloud and system scalability are also considered very important.
From this information, it can be seen that the high reliability and availability are the top issues for users, but there is also the fact that there are still many serious failure cases, and furthermore, many users want to have their system return to the on-premise from public cloud. Given these facts, we guess that users might be feeling quite confused and unsure as to how to implement mission-critical systems properly.
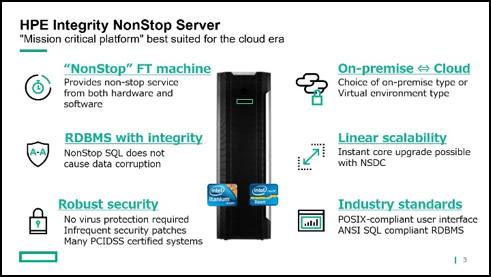
So we suggested that the only mission-critical system that solves this problem is none other than the HPE NonStop Server. The NonStop server is proud of its high availability and highly reliable RDBMS that does not cause data corruption. And you can choose the implementation as on-premises or in the cloud, and both are compatible because the same OS image is running. In addition, even with a sudden increase in transaction processing, NonStop Dynamic Capacity (NSDC) licensing can instantly and easily expand the system capacity without any downtime. These features are exactly what the users were looking for in the previous survey.
We believe NonStop Server is well known as “NonStop”, but in fact, it is also a big advantage for the customer that NonStop server does not cause data corruption which was reported as a terrible issue in case of database failures often seen in Japan.
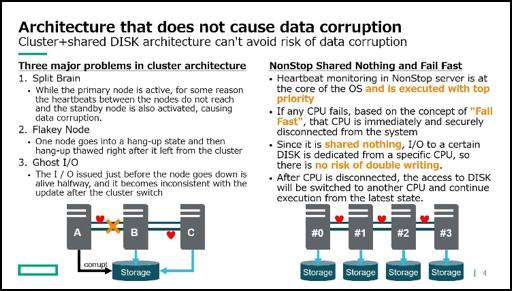
It works with end-to-end checksum scrutiny and transaction level data consistency guarantees with NonStop TMF, However, functions equivalent to these are also provided in other DBMS such as Oracle. The risk of data corruption is very architecture dependent. The combination of cluster system and shared DISK, as showed in the slide, if the control of the cluster does not work well, there is a risk of writing twice in the same data block by the multiple members. These problems have been recognized for 20 years, but they have not yet been completely resolved. NonStop servers, on the other hand, do not risk double writes due to the shared nothing architecture. Also, the process of disconnecting a processor from the entire system does not run in the application layer like cluster ware, but is executed with the highest priority in the core of the OS kernel, and is quickly and reliably disconnected. Therefore, it does not become unstable such as Split brain and Flaky node. This is the architecture that does not cause data destruction.
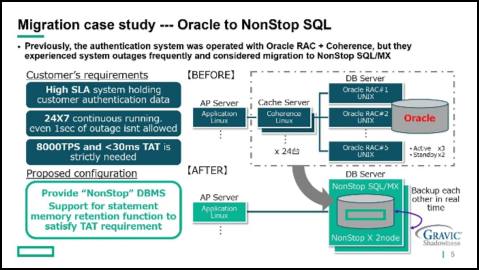
Next, we informed our customers that the NonStop server with such features will demonstrate its full potential when used as a mission-critical database server. No other database can offer such high availability and reliability. In Japan, there were cases where customers who had problems with Oracle moved to NonStop SQL and gained various advantages, and we introduced some of them. Another example is a customer who had built a large-scale authentication system with Oracle and many times they ran into serious database troubles and decided to migrate to NonStop SQL. About thirty Oracle servers were consolidated into two NonStop Servers, even while meeting the customer’s tough performance requirements. It’s been more than 3 years since the service started on the NonStop Server, and of course their business is still on NonStop today.
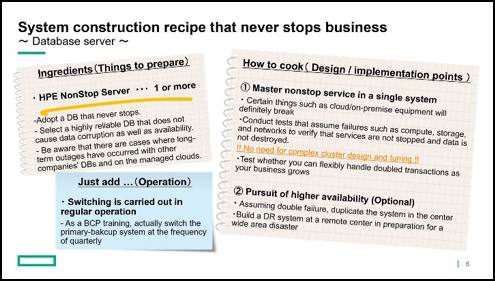
The last part of our seminar ended like this: In order to build a system that will not stop your business, be sure to select NonStop server as the only platform. Then, please do system testing to see how the system handles failures for each component. The huge amount of time required for high available design and tuning for cluster ware is totally eliminated. Also, if you want even higher availability, consider installing two NonStop systems and using a business continuity product to regularly switch the system that’s running in production as a normal operation. Doing so will result in a very robust system that can be deployed at low operating costs and will ensure your business continues to run even if there is a crisis like an earthquake.
About the authors
 Koji Tomita, MCS category manager
Koji Tomita, MCS category manager
Kouji Tomita has technology industry experience in product sales, business planning, business development, product management and marketing, including the last 22 years with Hewlett-Packard Enterprise. He is in charge of NonStop server category management in HPE Japan now.
 Susumu Yamamoto, Senior IT Specialist
Susumu Yamamoto, Senior IT Specialist
Since joining Tandem Computers in 1991, Susumu Yamamoto has been involved in various core system implementation projects as a pre-sales engineer for NonStop servers. Currently, as a Senior IT Specialist, he is leading the migration project from other companies’ databases to the NonStop database.

Be the first to comment